Note to Self: ROS tf
This post belongs to a brand new series I’m calling Note to Self, in which I’ll jot down bits of knowledge I’ve picked up along the way like pieces of gravel in my sneaker treads. It might be just a partial understanding of a concept that I plan to expand upon later, or maybe it just isn’t enough to warrant a full post. Either way, I hope you’ll find something useful here too.
I guess I decided to take a break from blogging for almost a month. Eventually my guilt got the best of me, so here I am. I’m still processing my experience with the Udacity Self-Driving Car Engineer Nanodegree capstone project, and the program as a whole. Expect a quick post once the official Nanodegree comes through, and of course a recap of the capstone project and a review of Term 3 and/or the program as a whole in the near future. In the meantime, I’ll just try to get back into the habit of blogging.
The SDCND capstone project is a complete ROS package with nodes for the various functions of Udacity’s real-life self-driving car, Carla. I’ll go into it more in a later post; for now I’ll focus on a particular aspect of the traffic light detector node - projecting a point onto an image plane. This node subscribes to, among others, a ROS topic containing images coming from Carla’s front-facing camera. Our task was to determine whether there is a traffic light in the image (particularly whether the traffic light is red) and, more or less, send this information along to other nodes.
Having done something similar in the Nanodegree Vehicle Detection project a few months prior, my (and I’m sure many other teams’) first inclination was to implement a sliding window or single-shot deep learning detector/classifier on the entire image. However, the starter code included a method stub for projecting a point in 3D space to a pixel in the camera image. We were also able to subscribe to a ROS topic which published a list of traffic light positions, as well as their current state (red, yellow, or green - although we were told it was meant for testing purposes only and would not be available when they evaluated submissions). This information could be used along with a broadcasted transform and the camera matrix to pull just the traffic light from the image. From there, it would be simple (and quick!) enough to use computer vision techniques to determine the color of the light. (And speed was of the essence - the provided simulator running alongside the ROS virtual machine was a huge drain on compute resources.) This approach appealed to me especially because I’ve cultivated an appreciation for anything that relieves our algorithm from relying on machine learning inference and reduces processing time. Really, why search the whole image if you know exactly where the object you’re looking for should appear? Eventually, I’d hope cities will have the infrastructure in place to broadcast traffic light states to all cars in the immediate area, but until then…
OK, let’s get to what we came here for: the ROS tf package. The package home page says:
tf is a package that lets the user keep track of multiple coordinate frames over time. tf maintains the relationship between coordinate frames in a tree structure buffered in time, and lets the user transform points, vectors, etc. between any two coordinate frames at any desired point in time.
What does that mean? Well, here’s a half-baked analogy: Imagine you’re standing in front of your house and you want to know your latitude and longitude. You could just check your GPS, but you forgot your phone at the office (Doh!). You can see that you’re so many meters east/west and so many meters north/south of your house, and you know your home’s address and that that’s a reflection of it’s distance east/west and north/south from some point near your city’s center, and you also happen to know the latitude and longitude of your city center. When you put all of these pieces together you can come up with a pretty good approximation of your own latitude and longitude - that’s the essence of frames and transformations in the ROS tf package.
If you have a humanoid robot, the hand may only know how its pose (position and orientation) relates to the forearm based on the bend of the wrist, and the forearm may only know how its pose relates to the upper arm based on the bend of the elbow, and so on. You can put all of these frames (e.g. /hand) and transformations (e.g. /hand to /forearm) together to find how the pose of any part relates to the pose of any other part. ROS keeps track of these in a tree structure like the one pictured below (viewable using standard ROS tf debugging tools like rosrun tf view_frames), and can even interpolate and extrapolate transforms to different points in time.

Here’s a really great depiction of how a tf tree might be implemented in a wheeled robot not too unlike our beloved Carla:
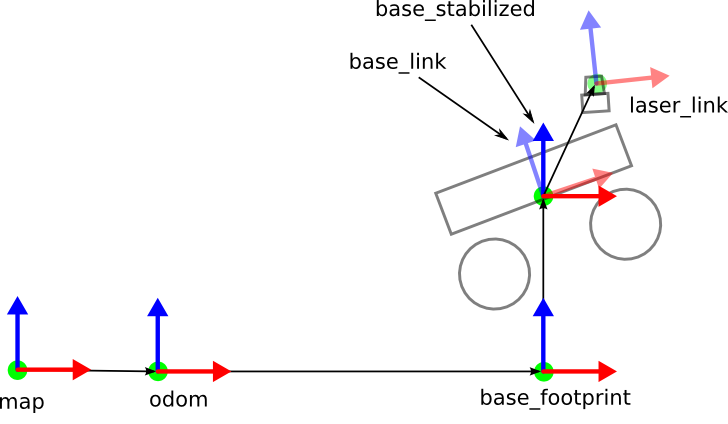
I took that image from this site, which looks pretty fantastic. I’ll definitely have to explore that one more later.
Anyway, back to our capstone project…
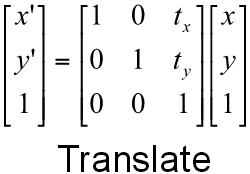
The transform listener lookupTransform method returns a tuple containing translation (as a list of x, y, z points) and rotation (as an x, y, z, w quaternion) information. One of my teammates had already used these, along with tf.transformations.euler_from_quaternion to extract a yaw angle in the x-y plane, and then used the familiar translation and rotation matrices (below) to manually transform the coordinates of the nearest traffic light from the /world frame to the /base_link (i.e. Carla, i.e. the camera) frame.
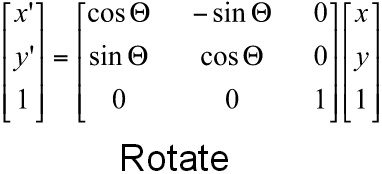
From there, the camera matrix was used to determine the pixel location of the traffic light center. After a few admittedly shady tweaks from yours truly, we were consistently pulling just the traffic light from the camera image. This worked well for the simulator, where our car traveled reliably in the x-y plane and yaw was the only non-zero component to the orientation vector, but I found later that actual Carla data contained in a rosbag included pitch and roll values in addition to yaw. I was going to have to convert the translation and rotation from 2D to 3D, which turns out to be considerably more complex. I thought, “Surely the tf package has a method for that!” And I was right - the transformListener class has methods for transforming all sorts of objects to and from different frames (I used transformPose for the traffic light). How did it work out? Well, you’ll just have to wait for my upcoming capstone report.
The ROS tf package wasn’t covered in A Gentle Introduction to ROS, but it’s obviously such an essential piece of ROS functionality. It’s something I’d been curious about for some time; I’m glad I finally got some experience with it.